The Semantic Web
By Joseph Herrmann, OCI Senior Software Engineer
February 2011
Introduction
Ever since the dot-com days of the late 1990s and early 2000s when it was first realized that the internet could be a source of massive revenue we have been awash in waves of recurrent hype and marketing. Often the hype turns out to be just that, as seen most dramatically in the bursting of the dot-com bubble. However, there are times when a new idea takes root and spawns an important new technology and/or business, and sometimes even opens up an entirely new market.
In technical fields where everyone is much too smart to be fooled by the sort of internet hype affecting the population at large we have learned to disguise our technological marketing shenanigans in clever ways so that we can more easily digest them and enjoy the exhilaration of being swept into the hype ourselves. Arguably, one good example of this is the use of the terms “Web x.0”, i.e. Web 1.0, Web 2.0, etc. The “Web x.0” terms are an attempt to describe the phases of evolution of the internet; a thing that has taken on a life of its own and a thing that is evolving in directions that we are hard-pressed to predict.
Web 1.0 is said to describe the internet as it existed from inception up to the bursting of the dot-com bubble. The emergence of Web 2.0 is ascribed to the dot-com bust. The problem with these “Web x.0” terms (or “jargon” as Tim Berners-Lee calls them) is that they have no well-defined meaning. With Web 1.0 there is at least the fuzzy notion of static, hyperlinked content. But ask ten people what Web 2.0 means and you will get ten different answers. Many cute and clever phrases have been pressed into service to describe Web 2.0:
- Web 1.0 was about reading, Web 2.0 is about writing
- Web 1.0 was about companies, Web 2.0 is about communities
- Web 1.0 was about advertising, Web 2.0 is about word of mouth
- Web 1.0 was about services sold over the web, Web 2.0 is about web services
- Web 1.0 was about home pages, Web 2.0 is about blogs
These sorts of phrases are obviously very general and encompass a wide variety of possible scenarios. They are far too vague to adequately describe the state of a system like the internet, much less anything else for that matter. One can argue that somewhere inside of this phraseology there exists the amorphous notion of some sort of collaborative social network with dynamic user interfaces, service-oriented applications, and so forth, but the term “Web 2.0” is sufficiently malleable as to describe a wide variety of possible evolutions. This is fortuitous for marketing departments far and wide.
Although the perspective taken thus far has been critical of the “Web x.0” terminology, it is not to say that it is not without some merit. There is an intuitive feeling that the internet will continue to evolve into the foreseeable future; no one can predict precisely how it will evolve, or in which directions, but only with hindsight will we be able to accurately describe its history. Thus, we use terms like “Web 2.0” in an attempt to describe where we are currently, and where we think we are likely to be going. This brings us to the next hypothetical evolution of the internet: Web 3.0, otherwise known as the “Semantic Web.”
Semantic Web: What Is It?
While the semantic web has often been presented with the same zest of hype as so many other things internet, at its core there exists a good, and perhaps essential, idea. This idea is very simple: the internet as it exists is, at best, fundamentally incomplete, and at worst, fundamentally flawed. The problem is that the internet operates mainly by processing and rendering data, but there is almost no capability to understand what the data means. Data is created, edited, deleted, received, stored, transferred, uploaded, downloaded, etc., and ultimately rendered. For a human user this is generally okay because a human can usually make inferences about the semantics (meaning) of data that is displayed through a combination of experience, intuition, and guesswork. However, machines have limited-to-no capability to make inferences about the meaning of any of the data they process or render, and thus their role in the internet is confined to that of "dumb" data-processors and data-rendering agents.
What is missing is the capability for machines to understand the meaning of the data. If they could know the semantics of the data, they would in many cases gain the ability to perform tasks that up until now are considered only possible through human operators. I venture to assert that this is the core idea of the semantic web.
Semantics: A Definition
Before we move ahead we need to define “semantics.” There is nothing mystical about this; semantics is synonymous with “meaning.” If someone asks “What is the semantic content of that piece of information?” it means the same thing as asking “What is the meaning of that piece of information?” This point is important to grasp because the word “semantics” is often used loosely to mean “syntax”, .e.g. “You two are arguing merely about semantics.” Semantics and syntax are two entirely different concepts: syntax refers to the way in which information is represented, and semantics refers to the meaning of the information. Syntax involves data or information representation, and semantics involves concepts and the relationships between them.
Semantic Technologies: What Are They Good For?
The subject of practical applications of semantic technologies is not without controversy. There have been research projects devoted entirely to identifying potential applications of semantic technologies, some with mixed results. Some of the literature on semantic technology fails to make a good case for practical applications. Either the literature fails to describe useful and practical applications, or else the examples that are presented are bogged down with so much technical jargon that a casual reader will not understand.
In making a case for the semantic web let us keep in mind that at one time the usefulness of hyperlinked text existing on a network was in question, and yet this led to the internet we know today. Even within the context of the current internet, new ideas are spawning applications that come online all the time. The full potential of the current internet has yet to be realized. Not every new idea or technology will be successful, in fact only a small percentage will. However, it is thought by some that semantic technology is different in this regard; it is thought that it is not merely a “good idea”, but instead is a fundamental piece of the internet that is currently missing. Tim Berners-Lee has described it as follows:
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web - the content, links, and transactions between people and computers. A 'Semantic Web', which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.”
A case has been made that the semantic web is more than just another good idea or application; this is a fundamental vision about the way the internet could, or should, work.
Implementation Obstacles
If the semantic web is such a great idea, why has it not yet been implemented? Much of the reason has to do with the way the internet started. Originally there was no notion of formally defined semantics in the internet. The concern was mostly about data and the rendering of that data. As time went on and the internet grew, standards were developed that did not include semantics as part of their specifications. Thus the internet has developed into a well-used system that unfortunately has no notion of well-defined semantics.
The internet provides value chiefly through the network effect: the more participants, the more value. When the internet was young there were few participants and relatively little value, except to curious technologists and researchers. As time went on more people joined, and the value went up proportionately. The same can be said of semantic technologies. At first when very little of the internet contains well-defined semantics, there is little value in adding semantics. But, as more of the internet space becomes “semanticized”, the value of semantic data will go up proportionately.
Semantic Applications
Now that we have a high-level idea of what semantic technologies are about, let's look at some hypothetical applications. One of the keystones in most semantic applications the idea of "smart data." Data as it currently exists in the internet will henceforth be given the pretentious title of “dumb data.” Here are some examples of each:
Dumb Data:
Disney World is in the list of places where there is a Holiday Inn, but Holiday Inn doesn't appear in the list of Disney World accommodations.
James Smith of 335 White Tree Lane exists in one database, and J Smith of 335 White Tree Lane exists in another. They are considered to be different.
Smart Data:
When you search for “bark” today you mean trees, but tomorrow you mean dogs.
The list of Disney World accommodations works both ways. Make them correspond.
People with the same name at the same address are the same person.
This gives us enough ammunition for the time being to examine a few ideas for practical semantic applications.
Context-Based Search Engine
The first example in the smart data section above about searching for “bark” illustrates the context-based search engine that many people will be familiar with. Many words have multiple meanings and obviously semantics can be used to disambiguate words and phrases to determine the correct underlying meaning.
Machine-Readable Web Content
Let’s say a software engineer is asked to attend a Spring conference. He brings up the conference’s web site and sees that it is being held in San Francisco from July 23-25. He goes to another web site to look up accommodations, and then navigates to a third web site to book his accommodations.
With semantics this entire process could, in theory, be automated. First the conference’s web site would need to contain metadata that offers information about the information on the page. The location and date of the conference would be marked as such with metadata. For example, the location information might look something like this in the html:
<p id="location" class="-ont-Location">123 Blah Drive</p>The line above specifies what is known as an RDF “triple.” RDF is a W3C specification for modeling metadata, but let's not concentrate on that yet; the important thing right now is that the triple contains two concepts linked by a relationship. Here we are saying that the html element known by id “location” is of type “Location.” The concept of “Location” exists in a semantic model (also known as an “ontology”) with name “ont.” The element with id “location” is linked to the concept of “Location” via a semantic relationship defined in RDF and known as “type.” RDF:type signifies that a resource is an instance of a class. So, the resulting triple looks something like this:
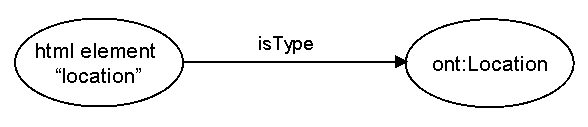
This is one method for adding semantic metadata to html: embedded RDF. The semantics of the data existing on a web page can be defined so that it is understandable to a machine. An automated agent looking at the conference web page would be able to know what the location and date is, and if other web sites contain similar semantic notions of locations and dates, the agent will be able to make associations between them.
Embedded RDF can be added to the website used to look up accommodations and the site used to book accommodations as well. Then an intelligent agent would be able to look up the location and date of the conference and associate these concepts to the web site used to look up accommodations, and also to the site used to book the accommodations. Once the semantics of the data has been well-defined, an automated process can make the associations required to accomplish a task such as booking the conference; it can perform tasks that span multiple web pages or applications. This is an example of the power of the semantic web.
Security: Authorization
The next example comes from an MIT technical proposal put together by Tim Berners-Lee some time ago. It illustrates the capabilities of logical deduction, which is a powerful aspect of semantic technology. Inference engines can perform deductive logic on ontological (semantic) models to deduce things about the semantics that are not explicitly defined in the models. The following example illustrates this within the context of user authorization.
The W3C site has certain content that is accessible only by members of the W3C member group. Each member organization has one Advisory Committee Representative (ACRep). The ACRep is responsible for managing and communicating access policies for the organization; the ACRep determines who within his organization may access the W3C as a representative of his organization. These representatives will be known here as “Reps.” The way this works in practice is each ACRep communicates their access policy to the W3C, which in turn configures their authorization system to implement the access policies.
As an example, ACME requires their ACRep to approve each and every Rep, whereas Zebco simply requires that anyone who can receive email in the zebco.com domain may act as a Zebco Rep. These two access policies are obviously very different, and there exists different access policies in the W3C authorization system for each. The diagram below shows this scheme:
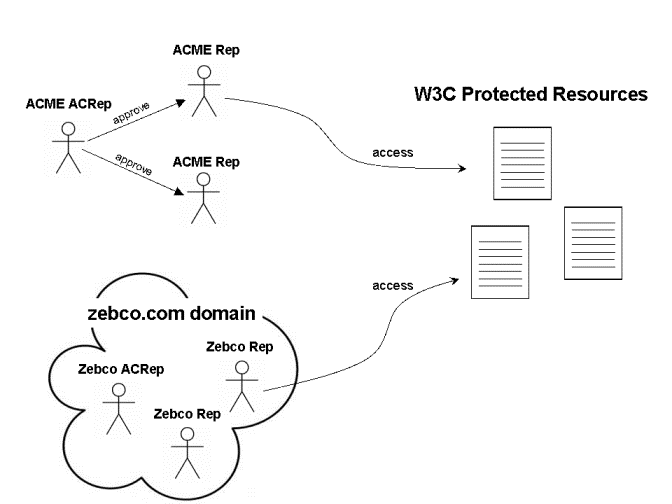
The approach for implementing the access control policies as described above is not a good model for the underlying social process. Any organization representative can access the restricted resources, yet it is ACReps that determine the access policies. The W3C web team must communicate with ACReps and manage and maintain various disparate access policies that in general can be unique to each member organization. This incurs a fair amount of overhead, and on top of this they have other classes of individuals that can access sensitive data such as invited experts, liaisons, etc.
Using semantics, the underlying social process can be modeled in a much more direct way using logical assertions. These logical assertions can be part of a semantic model and can enable an inference engine to make access control decisions.
First, let's add ACME to the W3C member group. The ACRep is an ACME employee named Wiley:
w3cDirector assures "ACRep(Wiley, ACME)"The above states that the W3C director asserts that Wiley is the ACRep for the ACME organization. Note that in the above, the semantic assertion may not be against Wiley directly, it could be against Wiley’s key or other form of trusted identity. Or alternatively it could indeed be against Wiley directly, who is an instance of an Employee concept existing in an ontological model.
Now let’s write an assertion that the W3C webmaster records his trust of the director on matters of member representation:
webmaster assures “for all org, rep((director assures “memberRep(rep, org)”) -> memberRep(rep, org))”Now, Wiley is going to make John Doe a Rep for ACME:
Wiley assures “memberRep(johnDoe, ACME)”Let’s control access of a meeting record so that only Reps can access it. In the below, K refers to any individual:
For all K, org(memberRep(K, org) -> has Access(K, meetingRecord)Now let’s say that John Doe wants to access the meeting record. The following assertion must be proven in order for him to be successful:
webmaster assures has Access(johnDoe, meetingRecord)Normally at this point John Doe would be required to submit some form of identification, but because this authorization system is based on semantics, there are a richer set of possibilities. A direct assertion that John Doe has access to the resources may or may not even exist, and if it does exist, it doesn’t have to reside on the W3C server. In the request a signed assertion that John Doe has access may be sent. Or, the W3C server may have this assertion already. Alternatively, a signed assertion may be sent stating that John Doe is a Rep of ACME, which would be sufficient to prove he has access. Or, the W3C server may find a signed assertion in some other disparate place on the internet, perhaps an identity repository containing a signed assertion that suffices to prove that he has access to the resource.
Hopefully this example gives a flavor for the richness of possibilities that deductive logic opens up. The thing to take out of this example is not necessarily the idea of implementing authorization systems with semantic technology but the more general concept of effectively modeling social processes.
Semantic Technologies: The Nitty-Gritty
There are many candidate technologies in the semantic web space. The intention in this short article is not to attempt to give an overview or explanation of each; instead we will delve into the most likely W3C candidates making up the semantic web standards stack:
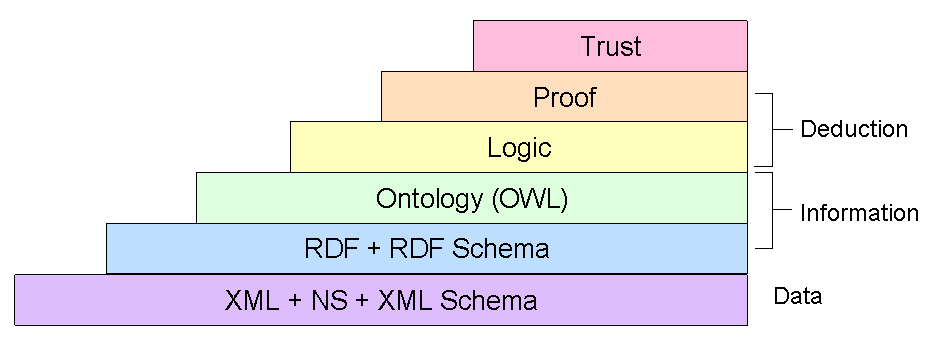
The first layer of the stack (XML) will be familiar to most readers. It can be argued that XML is the de-facto language with which to represent ontological models, although this is not true of all semantic applications. There are plenty of semantic applications that do not use XML as their representational language, but here we are going to focus mainly on the XML-based approaches.
RDF
Sitting above XML in the stack we have RDF and RDFS (RDF Schema). RDF (Resource Description Framework) is a W3C specification for representing metadata (data about data). At its core RDF describes triples. A triple contains a subject, predicate, and object:
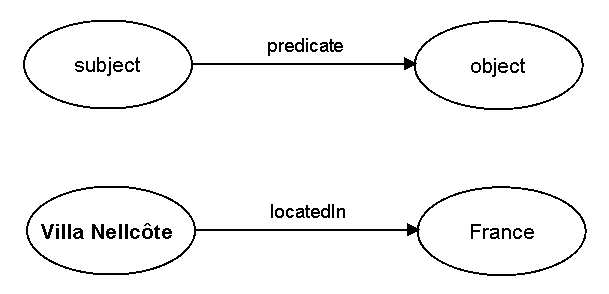
The set of triples described in an RDF model taken together makes a graph. The subjects and objects can be thought of as nodes in the graph, and the predicates can be thought of as the connecting arcs. Below is an example where RDF is used to represent a simple graph containing only two triples. Note that RDF can be represented in forms other than XML. Here we will look only at the XML style representation, sometimes known as RDF/XML:
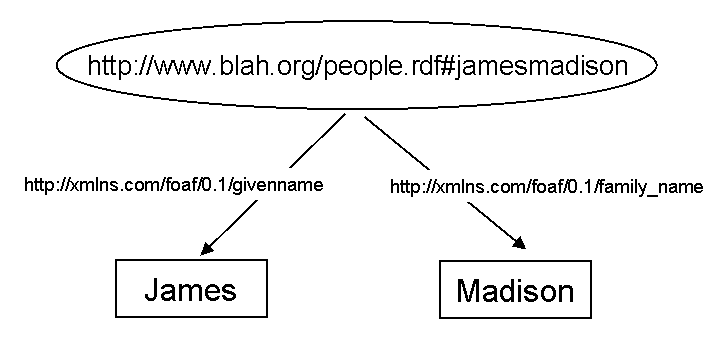
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf= http://xmlns.com/foaf/0.1/>
xmlns="http://www.blah.org/people.rdf#>
<foaf:Person rdf:about=" http://www.blah.org/people.rdf#jamesmadison">
<foaf:family_name>Madison</foaf:family_name>
<foaf:givenname>James</foaf:givenname>
</foaf:Person>
</rdf:RDF>After the initial namespace declarations, we first define the RDF subject as a person. “Person” here is defined in a third-party RDF vocabulary provided by the friend-of-a-friend project. After this, two foaf predicates are used (givenname and family_name) to define two objects, each of which contains a concrete piece of data related to the person, James Madison.
RDFS
While RDF provides a standardized way of building and representing subject/predicate/object triples (known generically as “vocabularies”), we are not yet to the point of constructing actual ontologies. RDFS helps to bridge the gap by introducing more abstract notions, such as the notion of a class. With the notion of class we can make statements such as X belongs to the class of entities Y. In fact, the RDF example above cheated a bit because foaf:Person is actually an RDFS class. When we wrote the RDF to say that James Madison is a foaf:Person, what actually happened behind the scenes is that we described an instance of the class foaf:Person known as James Madison that has an RDF:type relationship to the class foaf:Person.
OWL (Web Ontology Language)
Making the move from RDF to RDFS allows us to go from representing vocabularies to the representation of ontologies, but even so we are very limited as to the ontological models we can construct. RDFS essentially allows us to construct limited structural models. “Structural” means that while the models can contain classes, instances of classes, and relationships between them, there are no logical axioms included. We can include the notion of People, and England, and the notion of flying to England, but we cannot assert things like “People who have flown to England have been to England.”
Only by being able to model these sorts of logical assertions can we create full-fledged ontologies. OWL gives us these capabilities; the ability to model rich relationships such as equivalence, inverse, uniqueness, etc.
Some OWL Advantages:
Powerful ways to relate information:
- “people who have flown to England have been to England”
- “mountains are geological bodies”
- “a person with Multiple sclerosis has an inflammatory disorder”
Flexible ways to model sets of entities:
- “all mountains in the Appalachians”
- “people who have visited England”
- “incidents of Multiple sclerosis where the patient has Interleukin-6 biomarker”
Robust and powerful ways to re-use information:
- When the model was created we didn't expect people to be interested in the mountains in the Appalachian range, but we can define this set after-the-fact and draw conclusions about it.
A good example of an OWL ontology is the “pizza ontology” put together by the Protégé group out of Stanford. Protégé is a free open-source ontology editor that rivals many of its commercially-available alternatives. The pizza ontology is used in their tutorial to show the basics of constructing an ontological model. In this article we will not go into the use of Protégé, but in the interest of giving a brief example of an ontology and its use, let’s call into service Protégé’s pizza ontology.
Let's consider a hypothetical situation in which a person is interested in finding a pizza restaurant in town that serves vegetarian pizzas. While some restaurants may advertise their pizzas as vegetarian, others may offer veggie-only pizzas but not bother to advertise them as vegetarian. However, with semantics, it is possible to “figure out” that a restaurant serves vegetarian pizzas, even if they don’t explicitly classify them as such.
As an example of an OWL construct, here is a representation of a Quattro Formaggi (four-cheese) pizza:
<!--
Class: http://www.co-ode.org/ontologies/pizza/pizza.owl#QuattroFormaggi
-->
<owl:Class rdf:about="#QuattroFormaggi">
<rdfs:label xml:lang="pt">QuatroQueijos</rdfs:label>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasTopping"/>
<owl:someValuesFrom rdf:resource="#TomatoTopping"/>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Class rdf:about="#NamedPizza"/>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasTopping"/>
<owl:someValuesFrom rdf:resource="#FourCheesesTopping"/>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasTopping"/>
<owl:allValuesFrom>
<owl:Class>
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#FourCheesesTopping"/>
<owl:Class rdf:about="#TomatoTopping"/>
</owl:unionOf>
</owl:Class>
</owl:allValuesFrom>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>We see first that this pizza is a type of “named pizza.” Named pizza is a type of pizza that exists on a menu. In the interest of brevity the OWL representation of named pizza will not be shown here. Several restrictions are used to define the toppings that identify a Quattro Formaggi pizza. An OWL restriction describes the class of all individuals that satisfy the restriction. In the case of a Quattro Formaggi pizza, the toppings are a union of “four cheeses” and tomato. These toppings are, of course, ontological constructs themselves, and are defined elsewhere.
Our user is interested in vegetarian pizzas. Let’s say there is a restaurant that serves veggie-only pizzas, but they do not explicitly define them as being vegetarian. In this hypothetical example, the restaurant has made “semanticized” information about their menu available over the web, but in their semantics they've included no notion of a vegetarian pizza. Herein lies one example of the power of semantics: even though the restaurant has included no notion of vegetarian pizzas, the user can still search for them. In order to do this, the user must have available the concept of a vegetarian pizza. This is something the user can construct, or more likely it would come from an ontological repository. Here is an OWL representation of such a construct:
<!--
Class: http://www.co-ode.org/ontologies/pizza/pizza.owl#VegetarianPizza
-->
<owl:Class rdf:about="#VegetarianPizza">
<rdfs:label xml:lang="pt">PizzaVegetariana</rdfs:label>
<rdfs:comment xml:lang="en">
Any pizza that does not have fish topping and meat topping is a veg pizza.
</rdfs:comment>
<owl:equivalentClass>
<owl:Class>
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Pizza"/>
<owl:Class>
<owl:complementOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasTopping"/>
<owl:someValuesFrom rdf:resource="#MeatTopping"/>
</owl:Restriction>
</owl:complementOf>
</owl:Class>
<owl:Class>
<owl:complementOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasTopping"/>
<owl:someValuesFrom rdf:resource="#FishTopping"/>
</owl:Restriction>
</owl:complementOf>
</owl:Class>
</owl:intersectionOf>
</owl:Class>
</owl:equivalentClass>
</owl:Class>Here, OWL restrictions are used to define a vegetarian pizza by basically asserting that any pizza not having meat topping or fish topping is vegetarian.
At this point what transpires is the user submits a query against the semantic information made available by the restaurant, and an inference engine uses deductive logic to determine if any pizzas fitting the notion of a vegetarian pizza as defined above are available. In this way, the user can determine if vegetarian pizzas are available at restaurants even in cases where “vegetarian” pizzas are not explicitly listed on the menu, or even defined in their semantics.
Querying and Inference Engines
At the end of the last example the idea of querying semantic data and performing logical deductions was mentioned. In a short article such as this it is difficult to cover these subjects in detail; here a very brief overview of each will be given.
Semantic Queries
SPARQL (SPARQL Protocol and RDF Query Language) is the W3C’s specification for a semantic query language. It provides the capability to construct the types of queries necessary to extract the full value of information from semantic models, including the ability to construct structural queries as well as ask questions that involve logical deductions and use of axiomatic logic.
Inference Engines
Recall in the section comparing RDF, RDFS, and OWL that some ontologies are purely “structural”, whereas others include axioms that require logic deductions to fully extract the semantic value of a model. Logical deduction allows a semantic system to “figure things out” about information; things that are not explicitly or directly defined. This sort of deduction is carried out by inference engines. Unfortunately the subject of logical deduction, first order logic, and the like is beyond the scope of this paper.
Both commercial and free inference engines are available. Jena is an example of a free inference engine that supports transitive reasoning, RDFS rules, and OWL lite reasoning, among other things.
Conclusion
Semantic technologies/Web 3.0 is a controversial topic. It seems that for every proponent there is a skeptic with equally strong convictions. Part of the challenge semantic technologies face is in proving their worth in a technological environment that, as it is, is already producing so many things of worth. Proponents of semantic technology claim that it will propel the internet into entirely new, un-chartered directions and will result in extraordinary new value. Skeptics feel that the effort required to "markup" the internet to make it semantic will not be rewarded with anything of commensurate value.
Both sides have compelling arguments. Only time will tell.
References
The following are links of interest:
